Employment policies, broadly defined here as policies that aim to achieve the maximum amount of employment and/or achieve a living wage for employed individuals, are central tenets of both political parties. While the exact policies advocated for differ between the parties, these policies are seen to serve two primary objectives:
1. Bolstering the middle class (either through increasing its size from the bottom up or increasing its income).
2. Helping the poor and alleviating poverty by providing the poor with either more income or more employment opportunities.
These policies may be effective at achieving the first objective. Surely, the supposed effect on the middle class is the motivating political force behind these types of policies. However, given the types of individuals who find themselves in poverty, I believe that these employment policies play an out-sized role in our political discourse, especially when they are presented as a means to combat poverty.
To fully understand my position requires letting go of many prejudices about the “undeserving” poor. We are often told that the reason most people lack an adequate income is due to a “culture of poverty” which pervades in low income areas, or to a moral or academic failing of the individual impoverished person – therefore, they are “undeserving” of assistance. Overcoming this culture, this logic says, requires much work and an abundance of jobs; we should instill discipline in impoverished children through the harsh tactics practiced in many charter schools and ask low wage workers to work longer hours. After this discipline is achieved, it is vital to make sure that there are enough jobs available, and that they pay a living wage. One strategy, popular in the Republican party, is to bless job creators with tax cuts so that they have the means to provide more jobs. Other strategies, more commonly attributed to the Democratic party, are increases in job training and increases in the minimum wage.
While these measures may be well intentioned, they surely cannot solve, or even come close to solving, the problem of poverty in America. This is due to one simple fact that the “culture of poverty” types do not like to disseminate – the vast majority of the poor in America are not allowed to hold full time employment (children and students) or are not capable of holding employment (elderly, disabled, and their caretakers). This can be seen quite easily in the two charts below, created by Matt Bruenig at Demos. To create these charts, Matt uses census level data to break down the percentage of the poor population made up of children, elderly, disabled, students 18+, caretakers of disabled relatives, unemployed, employed, and “other” which are members of a poor household that are not in the labor force. These charts represent the “official poverty metric”, which takes into government transfer payments like social security, but not does not take into account food security programs like SNAP or the Earned Income Tax Credit.


If a culture of poverty truly inflicted the majority of these individuals, you would be hard pressed to find evidence in this chart. For example, if poor people were truly lazy, the vast majority of them should lie in the “other” category, meaning that they would be able bodied, working age, not employed, and not looking for a job. However, only 7.6% of poor individuals fall into the “other” category. It should also be noted that “other” does not only include the lazy, but also, for example, poor stay at home parents whose partner is in the workforce but cannot afford child care.
Reading this chart also makes clear that employment policies would do very little to alleviate poverty. Even if we could reduce the unemployment rate to 0% among the poor (we couldn’t), many of these formerly unemployed individuals would remain in poverty if they received a wage at or near the minimum. Furthermore, even if they all somehow escaped poverty (maybe there was an increase in the minimum wage), and all of the fully employed escaped poverty, 75% of poverty would still remain (this excludes all children that these people have, but even if all of these children were lifted out of poverty, 45% of poverty would still remain).
If we, as a country, believe that it is important to alleviate poverty, we cannot simply settle for employment policies. We must demand that our politicians create programs that directly affect, but are not limited to, those experiencing poverty. Personally, I support universal policies because their universal nature fosters political support; sadly, it is easier for many people to see the wisdom in cash grants if they receive one as well. Examples of such policies are a $300 per child per month cash grant for every child (not just the poor ones), free universal child care, or a universal basic income for all residents.



 if
if 
 otherwise.
otherwise.

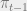 , is now smaller. In other words, the AS curve shifts down. The downward shift of the AS curve causes another decrease in inflation, and this process will repeat until the output gap is closed (i.e. output returns to potential, at the point short-run output = 0% in the above graph). We can see that the the economy above is self stabilizing for small demand shocks – that is, a small demand shock does not cause any explosive behavior, such as sending inflation to infinity or to negative 100%.
, is now smaller. In other words, the AS curve shifts down. The downward shift of the AS curve causes another decrease in inflation, and this process will repeat until the output gap is closed (i.e. output returns to potential, at the point short-run output = 0% in the above graph). We can see that the the economy above is self stabilizing for small demand shocks – that is, a small demand shock does not cause any explosive behavior, such as sending inflation to infinity or to negative 100%.




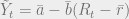

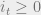

 is equal to the sum of the real interest rate and inflation. If we substitute this equation into the first, we have:
is equal to the sum of the real interest rate and inflation. If we substitute this equation into the first, we have: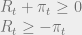 .
.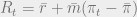 if
if 
 otherwise.
otherwise. ) will shift the AD curve. First, I will do a simple example using the AD curve without the ZLB to show what happens during “normal” recessions. Next, I will re-introduce the AD curve I just derived, and show that if the reduction in demand is large enough, the economy can get stuck in a deflationary spiral.
) will shift the AD curve. First, I will do a simple example using the AD curve without the ZLB to show what happens during “normal” recessions. Next, I will re-introduce the AD curve I just derived, and show that if the reduction in demand is large enough, the economy can get stuck in a deflationary spiral.



